大模型端侧部署正加速!AI PC等新物种热度暴增,企业对于AI加速卡的关注度也水涨船高。
但是AI PC等端侧设备中的AI加速卡如何做到可用、好用是一大难题,其需要兼顾体积小、性能强、功耗低才能使得端侧设备承载大模型能力成为现实。
近日,清华系AI芯片创企芯动力科技面向大模型推出了一款新产品——AzureBlade L系列M.2加速卡。M.2加速卡是目前国内最强的高性能体积小的加速卡,其强大的性能使其能够顺利运行大模型系统。
M.2加速卡的大小仅为80mm(长)x22mm(宽),并已经实现与Llama 2、Stable Diffusion模型的适配。

具备体积小、性能强,且有通用接口的M.2加速卡成为助推大模型在PC等端侧设备上部署的加速器。
从这一加速卡出发,芯东西与芯动力创始人、CEO李原进行了深入交流,探讨了大模型产业发展至今产生的显著变化,以及大模型在端侧部署过程中,芯动力科技在其中扮演的角色以及手持的杀手锏是什么。
AI PC已经成为大模型落地端侧设备的一个重要载体。
从去年年底至今,AI PC的热潮正在涌起。前有英特尔启动AI PC加速计划、高通推出专为AI研发的PC芯片骁龙X Rlite、上周英伟达发布全新一代RTX 500和1000显卡,支持笔记本电脑等端侧设备上运行生成式AI应用……
根据市研机构IDC发布的最新报告,预估AI PC出货量2024年逼近5000万台,到2027年将增长到1.67亿台,占全球PC总出货量的60%左右。
AI PC这一新物种正在加速大模型的规模化落地。与此同时,拥有庞大参数规模的大模型也对端侧设备可承载的算力提出了更高的需求。
在端侧往往只有一个独立设备。以PC为例,作为人们日常生活、工作的常用设备,其体积并不大且足够轻便,因此需要AI加速卡足够小且不会因体积牺牲性能上的优势。以M.2加速卡的形式进入AI PC的市场就是很有优势的产品形态。
可以看到,当下大模型的发展路线不再唯参数论,越来越多参数规模小性能强大的模型出现,如开源的Llama 2模型系列参数在70亿到700亿不等,为大模型在端侧的落地提供了机会。
即便如此,大模型想要成功部署在端侧对于芯片玩家而言仍然具有挑战,需要其突破端侧设备有限的计算和存储能力,因此芯片玩家亟需找到芯片体积小与性能强大的平衡点。
李原谈道,端侧设备还有一大特点是,GPU是其最主要的元件。这背后的风险在于,企业全部围绕GPU来做设备,就会造成一旦产品的开发周期变长,其未来的开发路线会受到一定限制。由于边缘设备上接口的可选择性不多,很多设备需要针对不同的芯片进行接口定制,企业就需要承担接口受限的风险。
这些新的变化及需求为这家GPGPU创企带来了新的机遇。
芯动力科技的AzureBlade L系列M.2加速卡,就是面对这一市场变化的最佳解决方案之一。
M.2加速卡搭载了4个DDR内存,总容量达到16GB,除了支持传统的视觉网络,如YOLO等,现在更已经实现了与Llama 2、Stable Diffusion等模型的适配。李原解释道,M.2加速卡目前可以支持70亿、130亿参数规模的Llama 2模型,以及最多可以支持300亿。目前,70亿参数规模的Llama 2在M.2加速卡上的计算速度可达到十几tokens每秒。
正与当下端侧的玩家承接大模型能力的核心痛点相对应,M.2加速卡的优势正是体积小、性能强,功耗低。
李原谈道,一般的GPU,NPU如果要处理大模型,因为算力要求高、功耗大,芯片面积也会比较大,很难集成在端侧设备狭小的空间内。M.2加速卡的大小仅为80mmx22mm,刚好能做到这一点。
达到这一优势的关键在于,芯动力科技为M.2加速卡集成了一颗芯片——AE7100,这颗芯片以17mmx17mm的面积实现了32 TOPs的算力与60GB/s的内存带宽。
 为了打造这颗足够薄且小的芯片,芯动力科技研发了一种创新的封装方案。他们一开始就在这个方向布局,去掉了芯片中的ABF材料,在无基板的情况下制造完成了芯片,还能满足其散热需求。“这也是我们第一次尝试这一封装工艺,并打造出了这颗业界最小、最薄的GPU。”李原说。
为了打造这颗足够薄且小的芯片,芯动力科技研发了一种创新的封装方案。他们一开始就在这个方向布局,去掉了芯片中的ABF材料,在无基板的情况下制造完成了芯片,还能满足其散热需求。“这也是我们第一次尝试这一封装工艺,并打造出了这颗业界最小、最薄的GPU。”李原说。
由于端侧设备的接口有限,芯动力科技为M.2加速卡选择了更为普及的闪存硬盘接口,这种接口已经普遍存在于PC等设备中,因此更容易被企业所接受,无需针对芯片进行接口定制就能快速实现相应的功能。
目前已经有诸多客户注意到了M.2加速卡,芯动力科技M.2加速卡的通用接口可以帮助企业规避定制风险,同时为其适配市面上的不同产品扩大可选择性。
与此同时,这一加速卡采用完全可编程设计,兼容CUDA+ONNX,可以广泛应用于AI PC、机器视觉、泛安防、内容过滤等领域。
在当下大模型逐渐迈向端侧设备、AI PC等新物种的热潮初现,支撑芯动力科技能够迅速推出创新的M.2加速卡,其关键基石在于——可重构并行处理器架构(RPP)。这正是M.2加速卡的核心AE7100背后的杀手锏。
RPP架构是针对并行计算设计的芯片架构,芯动力将其称作“六边形战士”。这一架构既结合了NPU的高效率与GPU的高通用性优势,更具备DSP的低延时,可满足高效并行计算及AI计算应用,如图像计算、视觉计算、信号处理计算等,大大提高了系统的实时性和响应速度。
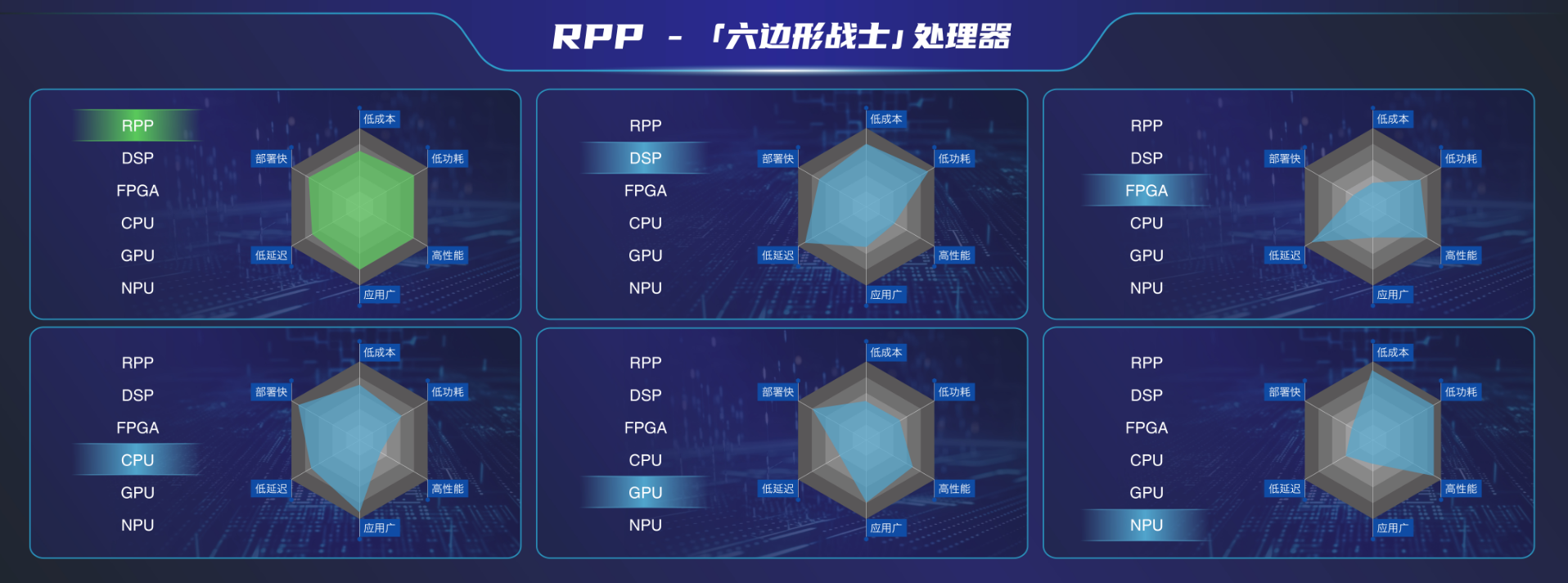
芯动力同样制程下的GPGPU芯片,与英伟达相比,在一些场景下性能提高达50%,且Core的面积为类似芯片的1/7,功耗仅为其1/2-1/3。
对这一架构的探索正是他们成立公司的最根本原因。芯片行业的发展周期很长,因此芯动力科技需要在保证芯片性能的同时,能适应5、6年之后市场的变化,这样才能在AI PC这样的机会出现时,迅速抓住机遇,打造出具有显著优势的产品。
对RPP架构的探索可以追溯到英伟达提出GPGPU新概念前后。彼时,芯动力创始团队就开始探索如何在发挥GPU并行计算能力和通用性优势的同时,通过引入其他类架构的长处,研发出能更好平衡性能、功耗、成本、延迟、部署速度的硬件。
因此,在2011年到2016年间,他们探索出独创的将NPU的高效率与GPU的高通用性相结合的创新架构,RPP架构应运而生。
芯动力科技将产品的开发周期定义为两个阶段,芯动力科技做的就是芯片的研制、基础软件研发,这样一来,针对企业的需求在这块基本成型的芯片上进行研发,只需要两三个月,就能达到产品性能,大大缩短芯片应用的时间周期。
这背后的考量就是芯片的市场推广。他补充说,目前AI发展处于早期,其落地的产品量相比于其他传统行业的设备而言并不算多,因此其产品定义仍然在快速变化中。以RPP架构为核心的产品出现,能前瞻性地瞄准通用性需求,满足芯片在更广泛场景下的应用,这就相当于他们面对最后的产品已经走了70%的路。
面向当下的市场变化,M.2加速卡已经快速向客户实现出货。目前M.2加速卡面向的客户主要为AI PC、工业视觉以及AI服务器厂商。目前,M.2加速卡已经向基因检测、AI服务器客户出货,AI PC厂商仍在进行产品的调校。
可以确定的是,芯动力科技的这一创新产品正让大模型在端侧迸发出无限的想象力。
大模型热潮为国内GPGPU公司带来诸多机遇,大模型在应用端的计算需求对于国内创企而言是一个巨大的机会。
对于芯动力科技而言,其创办之初就开始前瞻性地打造更加通用的产品,以RPP架构为核心打造产品适配企业客户更通用的需求,能更灵活应对复杂多变的市场趋势。
随着M.2加速卡规模出货、AI PC这一新物种的大规模量产,大模型在端侧将会的发展将会加速。芯动力科技也在大模型带来的产业变革下,热切寻找市场机遇。
可以看出,当下想要抓住产业机遇,核心的技术积累与前瞻性的技术布局更为关键。




